什么是N-Gram模型
N-gram是一种基于统计语言模型的算法,它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列。
每一个字节片段称为gram,对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一种gram就是一个特征向量维度。
该模型基于一种假设,第N个词的出现只与前面N-1个词相关,而与其他任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。常用的二元Bi-Gram和三元Tri-Gram。
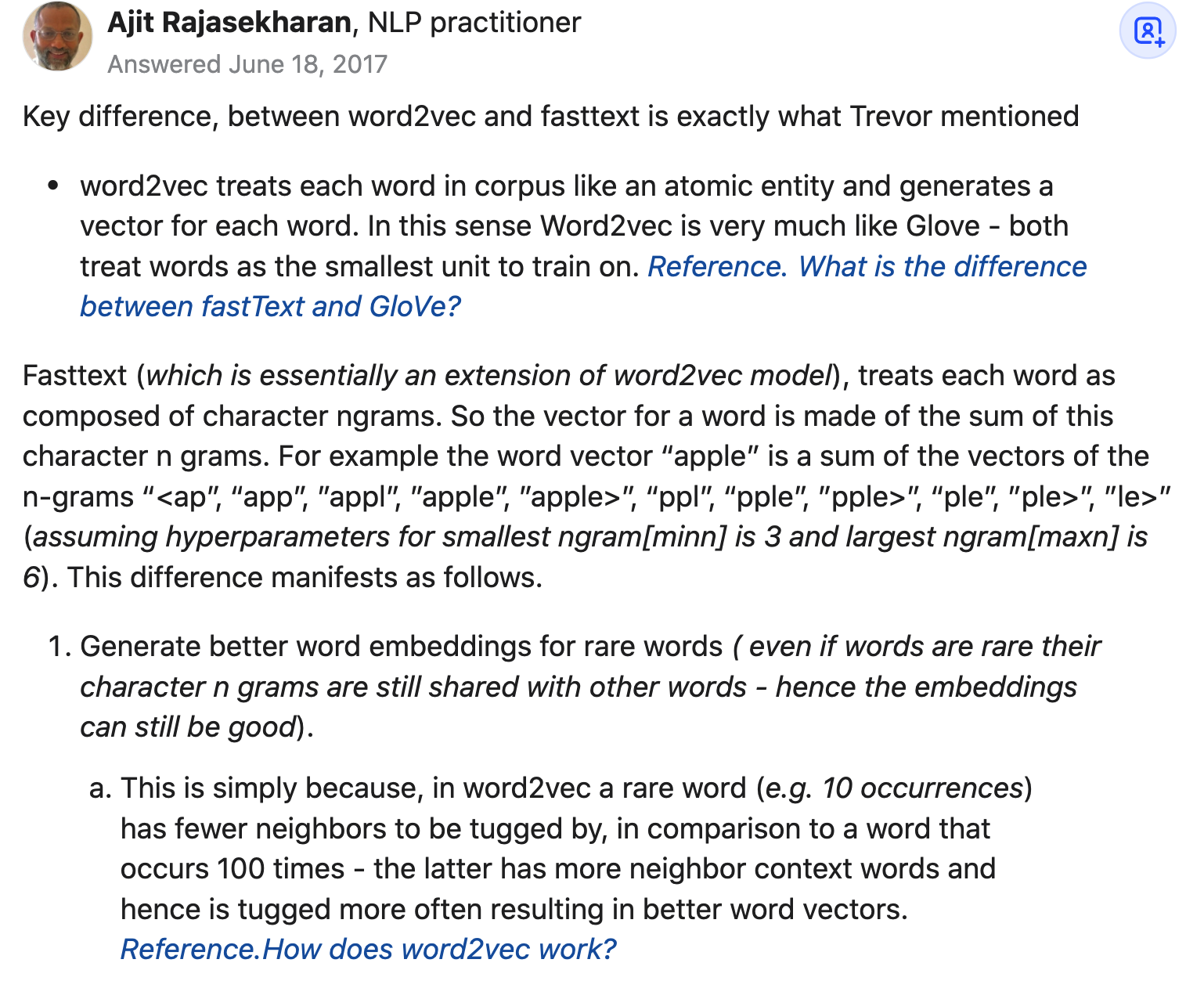
Word2vec和Fasttext有什么不同呢?
Word2vec在训练集里是针对每一个词进行训练的,最小的训练粒度是词,从这一点来说Glove跟Word2vec是非常相似的,那可以看下fasttext和Glove有什么区别:
Glove和Word2vec都是以词语为最小粒度进行训练
Fasttext是wordvec的一种拓展,最小训练粒度是字符,(treats each word as composed of character ngrams),然后特征向量是由这些ngrams字节进行求和组成
这种特性让fasttext有以下的特点:
- 针对稀有词能有更好的embedding向量,因为稀有词也是由ngrams字节组成
- out of vocabulary words,即使训练集中没有的词语,fasttext也能根据ngrams字节构造其特征向量
比如词语 apple,
是由以下ngrams字节的向量求和构成:
‘
(最小ngram为3,最大ngram为6的情况)
这种区别导致了以下特点:
能更好的训练出稀有词的embedding
因为在word2vec中稀有词拥有的邻居词更少,而高频词出现的次数多,导致高频词的embedding结果会比稀有词好
即使词语没出现在训练集中 fasttext也能构造出其特征向量
fasttext的embedding结果好坏,超参数起到了关键的作用
超参数中的最小ngram和最大ngram直接影响到最后的结果
随着训练集的增大,内存的要求也会增长
Quora的原文回答:


参考资料
fasttext: https://arxiv.org/pdf/1607.01759.pdf
https://cai.tools.sap/blog/glove-and-fasttext-two-popular-word-vector-models-in-nlp/
https://www.quora.com/What-is-the-main-difference-between-word2vec-and-fastText